Mennesker lærer af erfaring. Maskiner lærer af data.
Interessen for Machine Learning er steget markant i løbet af de sidste år, men for mange er det stadig mest et buzz word. Her vil jeg prøve at bringe det lidt ned på et niveau som de fleste kan relatere til, nemlig ved at lave lidt Machine Learning i Excel. Machine Learning behøver ikke være mere kompleks end det.
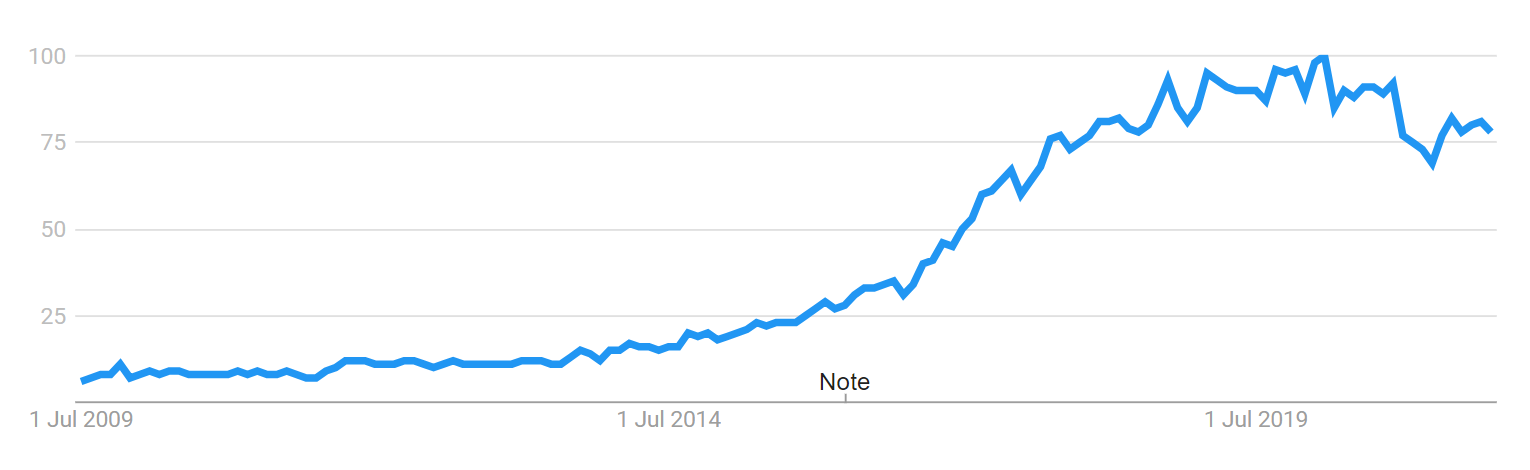
Antal ord og organisk trafik
Som eksempel på machine learning der kan laves i Excel, vil jeg analysere forholdet mellem længden på blogindlæg og mængden af organisk SEO trafik. Sammenhængen er bevist flere gange tidligere, fx af Backlinko:
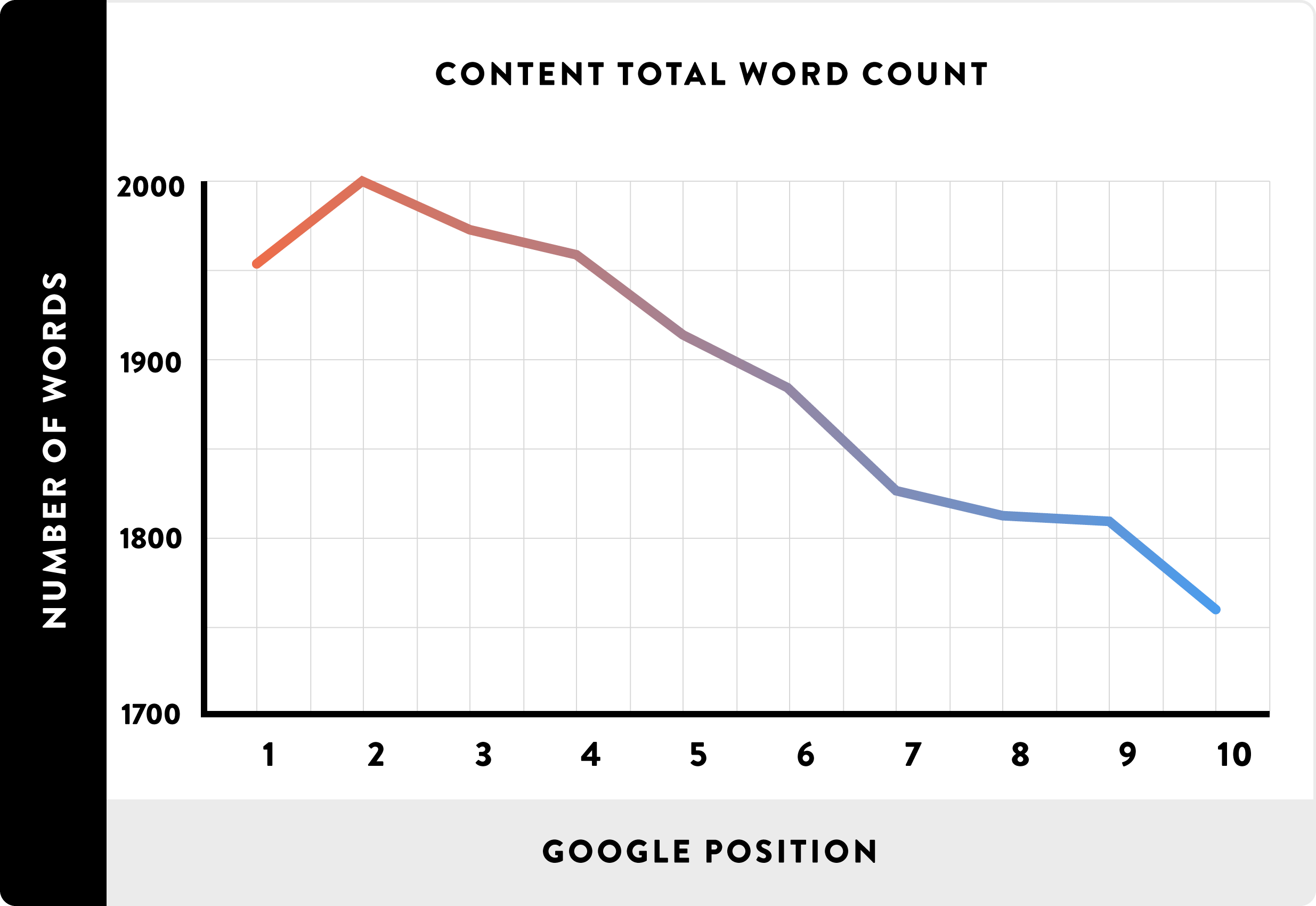
Rand Fiskin har dog et helt andet take på det i denne Whiteboard Friday:

The perfect blog post length and frequency is bullshit
Her vil jeg derfor analysere hvor meget længden af indlægget betyder for trafikken på min personlige blog og endnu mere spændende: Om man kan forudsige hvor meget trafik et blogindlæg vil få, baseret på antal ord = prædiktiv analyse.
Først har vi brug for noget data
Vi skal bruge et datasæt som indeholder antal ord i hvert blogindlæg samt antal organiske sessioner der er startet på hvert blogindlæg. Der er flere måder at få antal ord på. Man kan gøre det manuelt, men det gider vi ikke, så vi får WordPress til at gøre det for os, ved at indsætte denne funktion i functions.php:
function word_count() {
$content = get_post_field( 'post_content', $post->ID );
$word_count = str_word_count( strip_tags( $content ) );
return $word_count;
}
Derefter kan antal ord i hver blogindlæg nemt udstilles i dataLayer sådan her:
window.dataLayer = window.dataLayer || [];
dataLayer.push({
'words': '<?php echo word_count(); ?>'
});
I Google Analytics har jeg så opsat en hit-scoped Custom Dimension, hvor jeg kan opsamle antal ord for blogindlægget, når det bliver besøgt.
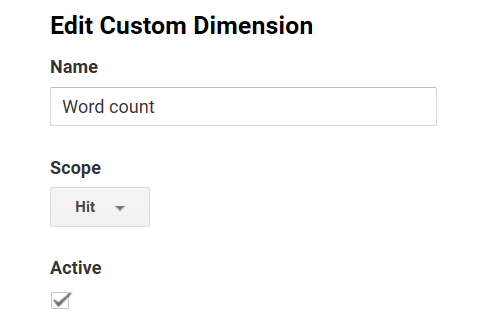
Antal ord i hit-scoped custom dimension
Derefter vælger jeg rapporten Acquisition -> All traffic -> Channels og vælger Organic Search. Jeg vælger Landing Page som primær dimension og den nye custom dimension Word Count, som sekundær dimension og får dermed dette udtræk, som eksporteres til Excel.
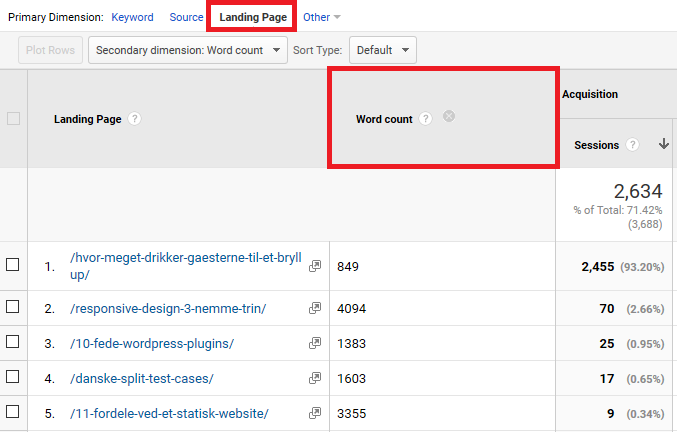
Datasættet med landingpage, antal ord og organiske sessioner.
Okay, så nu har vi styr på datasættet. Så skal vi igang med noget Machine Learning.
Der er tre typer af Machine Learning
Indenfor Machine Learning er der tre primære grupper af analyser du kan lave:
- Unsupervised learning: Kan der findes nogle interessante mønstre i datasættet?
- Supervised learning: Kan man forudsige noget på baggrund af disse data?
- Reinforcement learning: Analyse der automatisk bliver klogere af sig selv på baggrund af en række regler, fx, find den optimale strategi i skak
I dette indlæg kigger vi på de to første. Lad os starte med den første:
Unsupervised learning
Det første skridt er at undersøge om der er en sammenhæng mellem de to variabler. I statistik kaldes de to to variable for den uafhængige variabel (antal ord) og den afhængige variabel (organisk trafik). Vi prøver altså at undersøge om organisk trafik er afhængig af antal ord.
Er der en sammenhæng? (Scatter Plot)
Det kan være svært at se om der er en sammenhæng ud fra en tabel med data, så lad os lave lidt simpelt data visualisering med et Scatter Plot.
Hver prik er et blogindlæg og akserne er hhv. antal ord i artikel og organisk trafik til blogindlægget.
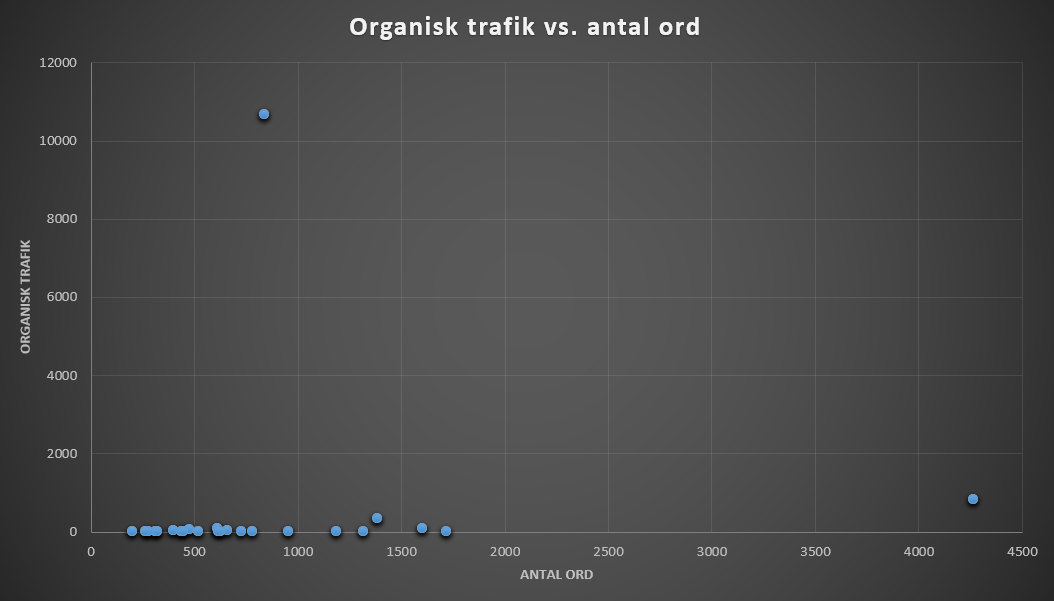
Scatter plot af alle mine indlæg.
I første omgang er det svært at se om der er en sammenhæng, da de fleste er klumpet sammen nede i hjørnet. Det skyldes outliers, dvs. observationer i datasættet, som ligger markant uden for normalen. Ekstreme tilfælde er svære at arbejde med, da de vil få alt for stor indflydelse på modellen. Vi ønsker primært at arbejde med data indenfor normal-området.
De to outliers er:
1) Mit indlæg om drikkevarer til et bryllup, som får ekstremt meget trafik, sammenlignet med mine normale indlæg om digital marketing, så derfor fjernes den fra modellen.
2) Den anden outlier er mit indlæg om responsivt web design i 3 nemme trin som er på 4253 ord, som er markant længere end mine øvrige indlæg, så derfor fjerner jeg også den.
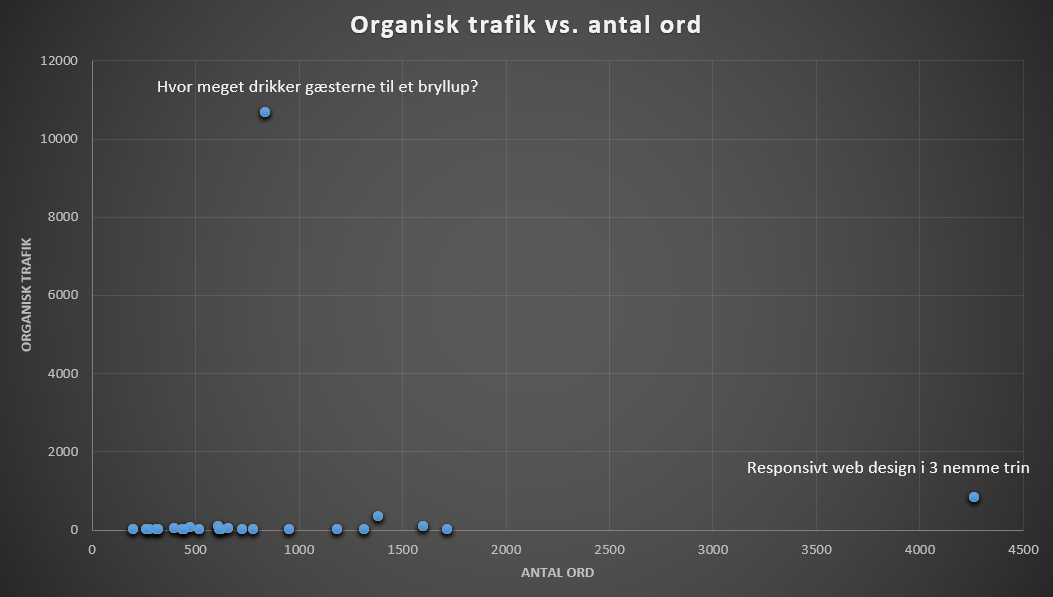
De to outliers der forvrænger data.
Nu er det mere tydeligt at se en sammenhæng, hvor blogindlæg med flere ord også har mere organisk trafik.
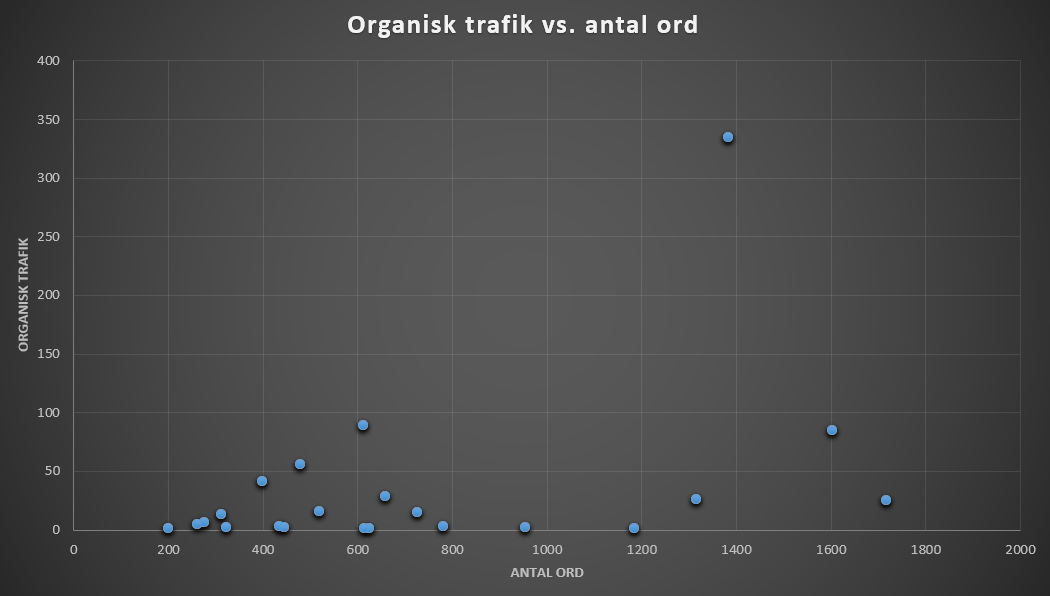
Scatter plot uden outliers.
Vi kan gøre det lidt tydeligere, ved at tilføje en tendenslinje.
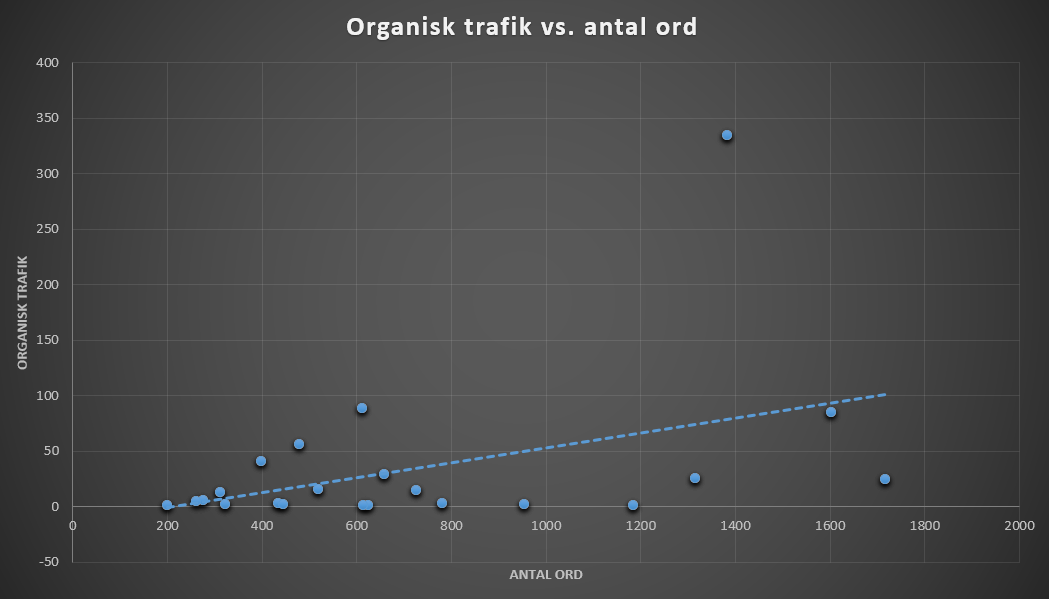
En tendenslinje fremhæver sammenhængen.
En tendenslinje gør for det første sammenhængen tydeligere, men den viser også hvor konsistent sammenhængen er i datasættet. Jo tættere alle prikkerne er på linjen, jo mere konsistent er relationen mellem tekstlængden og trafikken. Jo længere prikkerne er fra linjen, jo mere tilfældigt er det og dermed vil dataene typisk ikke være gode at bygge en model på.
Hvor stærk er sammenhængen? (Korrelation)
Hvis der er perfekt korrelation, kan man forudsige værdien af den ene variabel, kun ved at kende den anden.
Korrelation udtrykkes som et tal mellem -1 og 1. Jo tættere på yderpunkterne, dvs. -1 eller 1, jo stærkere er korrelationen.
Lad os tage et par eksempler.
Her er først et datasæt med en korrelation på 1, dvs. når den ene stiger, så stiger den anden også.
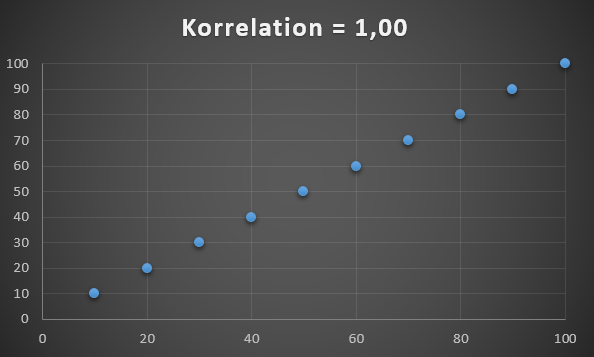
Datasæt med korrelation på 1.
Det kan for eksempel være personers højde og vægt som ofte følges ad. I den virkelige verden vil man dog typisk aldrig opnå en korrelation på 1,0 da der vil altid være outliers.
Den omvendte er et datasæt med en korrelation på -1, dvs. en negativ korrelation. Det vil altså sige når den ene stiger, så falder en anden.
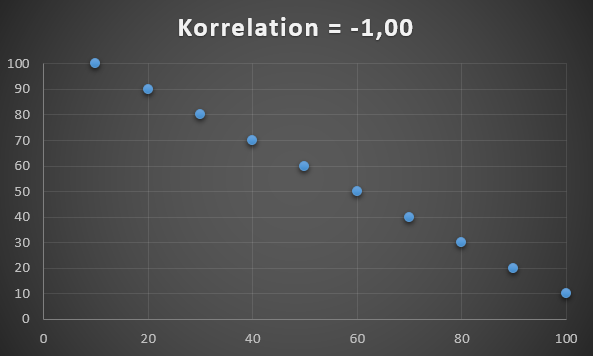
Datasæt med korrelation på -1.
Det kan fx være sammenhængen mellem hvor koldt det er og hvor mange penge man bruger på at opvarme sit hus.
Det sidste eksempel er et datasæt med en korrelation tæt på 0, dvs. der er ingen sammenhæng mellem de to variabler. Dermed er det umuligt at forudsige hvad den ene værdi vil være hvis man kender den anden værdi.
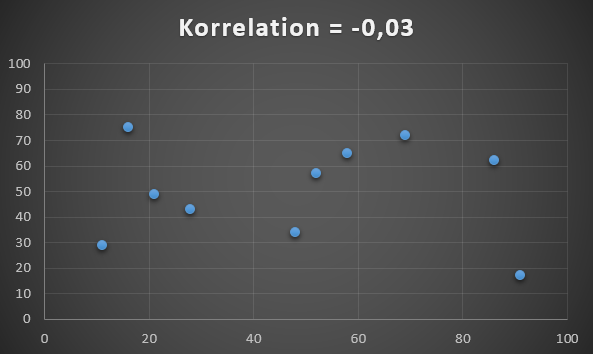
Datasæt med korrelation på 0,03.
Det kan fx være en persons højde og karakter i skolen, hvor der formentlig ikke er nogen som helst sammenhæng, og det er dermed helt tilfældigt hvor prikkerne er placeret, som det ses herover.
Korrelation mellem antal ord og organisk trafik
I disse data er korrelationen mellem antal ord og organisk trafik på 0,63.
Korrelation på 0,63.
Årsag eller sammenhæng?
Okay, så nu har vi fundet ud af at der er en sammenhæng mellem de to variabler. Årsag er en helt anden ting.
Det vi gerne vil undersøge her er nemlig ikke blot om der er en sammenhæng mellem antal ord og organisk trafik, men også om antallet af ord kan forårsage (eller forklare) trafikken og dermed om man kan konkludere at hvis man skriver flere ord, så får man også mere trafik og omvendt.
Når vi snakker årsag så er der tre muligheder:
- Antal ord påvirker mængden af organisk trafik. Det er en sandsynlig forklaring.
- Organisk trafik påvirker antal ord. Det giver ikke nogen mening. Der kommer ikke flere ord i en artikel, hvis den begynder at modtage mere organisk trafik, så væk med den.
- Både antal ord og organisk trafik bliver påvirket samtidig af en helt 3. faktor. Den kan også være en sandsynlig forklaring. Forklaringen kan være at årsagen bare er gode velskrevne blogindlæg, som både får meget trafik og at velskrevne blogindlæg også ofte er længere. Dvs. man kan ikke bare skrive længere blogindlæg. Man skal skrive bedre blogindlæg, for at få mere trafik.
Ingen kan forklare korrelation bedre end hende her, så lad os give hende 5 minutter og så fortsætter vi derefter.
Giver det mening?
Det bedste du kan gøre for at afgøre om den ene variabel forårsager den anden variabel eller der blot er en sammenhæng er at spørge dig selv om det giver mening?
- Lange tekster indeholder meget information om et givent emne og er derfor gode at henvise til.
- Lange tekster kommer i bund med et emne.
- Lange tekster dækker mange aspekter af et emne og brugeren skal dermed kun søge information ét sted.
Alle sammen er faktorer som gør at Google gerne vil ranke indholdet højt.
Tidligere undersøgelser har vist en sammenhæng mellem lange tekster og deres placering i Google.
Supervised learning
For at lave en model som kan forudsige organisk trafik baseret på antal ord kan vi lave en regressionsanalyse.
Regression
En regressionsanalyse kan laves direkte i Excel og giver følgende resultat for vores data.
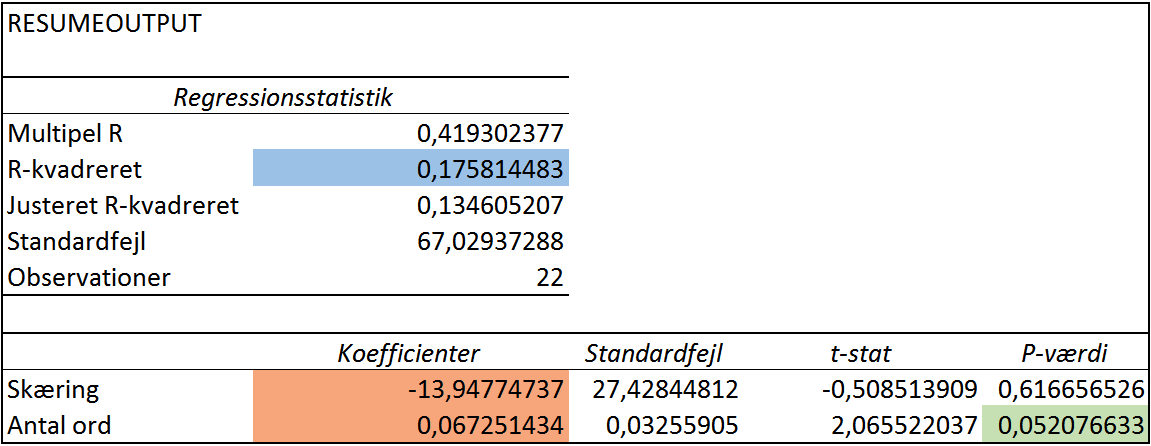
Resultatet af den linære regression.
Den blå kasse hedder R squared på engelsk, også kaldet forklaringsgraden. Den viser at 17,5% af variationen i den afhængige variabel (organisk trafik) kan forklares af modellen. Og eftersom der kun er én uafhængig variabel i modellen (antal ord), så kan vi altså sige at antal ord forklarer 17,5% af variationen i organisk trafik. Eller sagt på lidt mere dansk: Antal ord forklarer 17,5% af den organiske trafik et blogindlæg har. Resten af variationen (82,5%) kan ikke forklares af modellen, og skyldes dermed andre faktorer, som er alle de andre ting Google kigger på, når de ranker indhold.
Hov hov, nu ikke så hurtigt!
Men husk at vi ikke kan konkludere at antal ord alene forklarer 17,5% af trafikken. Som tidligere nævnt kan det sagtens være en andre ting, som dog korrelerer stærkt med antal ord, fx en velskrevet artikel, som får mange sociale delinger, links, høj CTR, etc.
Forudsige organisk trafik
Okay, nu skal vi lige et smut ned af memory lane. Vi skal tilbage til linoleumsgulve og folkeskolens matematiktimer. Kan du huske linjens ligning?
Altså den her: Y = A * X + B
Hvor A er hældningen på linjen og B er skæringen med Y-aksen. Det er de to tal regressionsanalysen kan udregne for os.
Når vi kander A og B kan vi indsætte antal ord som X og udregne den forventede organisk trafik. Vi skal derfor have linjens ligning for tendenslinjen herunder.
Linjens ligning for tendenslinje kan forudsige trafikken.
De to tal vi skal bruge til at indsætte istedet for A og B i ligningen får vi altså som en del af resultatet af den linære regression. Det er de to tal i den orange boks.
De to orange tal er A og B i linjens ligning.
Det første tal er skæringen med Y-aksen som er -13,95.
Det næste tal er hældningen på linjen som er 0,067.
Dermed bliver linjens ligning: Y = 0,067 * X – 13,95
Hvis vi fx indsætter X = 5000, får vi følgende: 321,05 = 0,067 * 5000 – 13,95.
Det vil altså sige at den forventede organiske trafik til et blogindlæg på 5000 ord er 321 besøg i samme periode som de øvrige tal er udtrukket for. I dette tilfælde har jeg trukket 1 års besøg ud, så perioden er 1 år.
Hældningen på linjen fortæller desuden at hver gang X stiger med 1, så stiger Y med 0,067.
Sagt på dansk: Hver gang vi skriver et ord mere, så kan vi forvente 0,067 flere besøg om året.

1 kommentar
Tak for en så detaljeret analyse, som tekstforfatter har jeg nu en opgave med at gøre tekster på vores hjemmesider mere længere og med flere søgeord, nu forstår jeg årsagen til det.